

Կարո՞ղ է մեծ լեզվական մոդելը «կարդալ» մոլեկուլների կառուցվածքներն ու սովորել քիմիա․ այս հարցը երկու տարի առաջ հետաքրքրեց մի խումբ հայ գիտնականների: Հարցի պատասխանը ստանալու համար միավորվեցին Մոլեկուլային կենսաբանության ինստիտուտի Բջջային տեխնոլոգիայի լաբորատորիայի կենսաբանները, մեքենայական ուսուցման հետազոտություններով զբաղվող YerevaNN լաբորատորիայի գիտնականները, Արմեն Աղաջանյանը՝ Meta AI-ի գիտական թիմից, ինչպես նաև Toxometris.ai ստարտափի հետազոտողները։
Journal of Chemical Information and Modeling ամսագրում գիտնականների համահեղինակությամբ օրերս հրապարակված հոդվածը տալիս է այս հարցի պատասխանը։
Մոլեկուլները՝ տեքստային լեզվով
Մեքենայական ուսուցումը Արհեստական բանականության ճյուղ է, որի միջոցով ստեղծվում են համակարգչային մոդելներ։ Այս մոդելները, ուսուցանվելով մեծ քանակությամբ տվյալների հիման վրա, կարողանում են կանխատեսումներ իրականացնել և այլ հանձնարարություններ կատարել: Կախված խնդրից՝ գիտնականներն ընտրում են, թե ինչպիսի տվյալներով ուսուցանեն մոդելները և ուսուցման ինչպիսի մեթոդ կիրառեն։
Մեծ լեզվական մոդելներն (large language models), օրինակ, ուսուցանվում են տեքստերով․ մոդելներին տրվում են որևէ լեզվով, օրինակ՝ անգլերենով գրված միլիարդավոր տեքստերի օրինակներ։ «Կարդալով» այս տեքստերը՝ մոդելները կարողանում են հասկանալ տվյալ լեզվի օրինաչափություններն ու հետո ինքնուրույն տեքստեր գեներացնել։ Հենց այս սկզբունքով է ուսուցանվել, օրինակ, շատերիս հայտնի ChatGPT-ն։
Հիմա պատկերացրեք, որ նույն կերպ մեծ լեզվական մոդելները կարողանում են «կարդալ» նաև մոլեկուլների կառուցվածքները։ Գուցե սա առաջին հայացքից զարմանալի թվա, քանի որ մոլեկուլները գրվում են քիմիական բանաձևերով. օրինակ՝ ածխաթթու գազի քիմիական բանաձևն է CO₂-ը։ Սակայն դեռևս 1980-ականներից գոյություն ունի մոլեկուլների գրության մեկ այլ ձև, որը հասկանալի է համակարգիչների համար։ Խոսքը SMILES ներկայացման համակարգի մասին է, որը հնարավորություն է տալիս անգլերեն տառերով և նշաններով արտահայտելու մոլեկուլների քիմիական բանաձևերը` մոլեկուլների մաս կազմող ատոմները և դրանց միջև գոյություն ունեցող քիմիական կապերի տեսակները։ SMILES համակարգում CO₂-ն, օրինակ, կգրվի այսպես՝ O=C=O:
Այսպիսով, իրենց մեծ լեզվական մոդելը մոլեկուլների կառուցվածքներով ուսուցանելու համար գիտնականները նախ վերցրին 1,7 միլիարդ մոլեկուլներ պարունակող տվյալների բազա և բազայի բոլոր մոլեկուլներն արտահայտեցին տեքստային ֆորմատով։
Արմեն Աղաջանյանը, որն աշխատում է Meta AI-ի գիտական թիմում, տեքստային ֆորմատով արտահայտված մոլեկուլներով նախնական ուսուցում (pre-training) իրականացրեց՝ օգտագործելով ժամանակին Meta AI-ի ստեղծած BART մեծ լեզվական մոդելը։
Ուսուցանման ընթացքում BART մոդելին չէին տրվում մոլեկուլների՝ տեքստային տարբերակով արտահայտված ամբողջական կառուցվածքները․ կառուցվածքների որոշ հատվածներ բաց էին թողնվում, և մոդելը պետք է սովորեր լրացնել այդ հատվածները։
«Այս թվացյալ պարզ գործողության արդյունքում մոդելը սովորեց տարրական քիմիա, սկսեց պատկերացում կազմել, թե ինչպես են ատոմները, իրար հետ փոխազդելով, ստեղծում բարդ քիմիական միացություններ»,- պատմում է հոդվածի համահեղինակ Զավեն Նավոյանը։
Իրենց ստացած մոդելը գիտնականները կոչեցին BARTSmiles․
BARTSmiles-ը սկսեց ճիշտ կանխատեսումներ իրականացնել
Այս նախնական աշխատանքն անելուց հետո գիտնականները պետք է համոզվեին, որ BARTSmiles-ը իսկապես «քիմիա է սովորել» և մոլեկուլների հատկությունների մասին բավականաչափ գիտելիքներ ունի։
Այս փուլում հետազոտությունները տեղափոխվեցին հայաստան՝ Հրանտ Խաչատրյանի ղեկավարած YerevaNN լաբորատորիա, քանի որ մեծաքանակ տվյալներով նախնական ուսուցումից հետո հետագա վերաուսուցումը (fine-tuning) հաշվողական ավելի քիչ ռեսուրսներ էր պահանջում և հնարավոր էր իրականացնել Հայաստանում։
Գոյություն ունեն տվյալների տարբեր բազաներ, որոնք պարունակում են մեծաքանակ մոլեկուլների և դրանց տարբեր հատկությունների մասին տեղեկություններ։ Մոդելի հետագա ուսուցման համար գիտնականները վերցրին այդպիսի երկու բազա։ Բազաներից մեկը պարունակում էր մոլեկուլների լուծելիության մասին տվյալներ, մյուսը՝ մուտագենության (մուտագեն են այն մոլեկուլները, որոնք, հայտնվելով օրգանիզմում, գեներում առաջացնում են մուտացիաներ (փոփոխություններ)՝ պատճառ դառնալով տարբեր հիվանդությունների, օրինակ՝ քաղցկեղի)։
Այնուհետև գիտնականները այս բազաների տվյալներով վերաուսուցանեցին BARTSmiles-ին։ Պատկերացնենք, որ մոդելը տվյալները ստանում էր աղյուսակով, որն ուներ երկու շարք․ առաջին շարքում ներկայացված էին տվյալների բազայից վերցված մոլեկուլների կառուցվածքները, երկրորդ շարքում՝ ամեն կառուցվածքին համապատասխան հատկությունը (որքա՞ն է ջրում լուծելիության աստիճանը կամ արդյո՞ք մուտագեն է, թե՞ ոչ):
Այս տվյալներով վերաուսուցանվելուց հետո մոդելն արդեն ինքն էր կարողանում կանխատեսել մոլեկուլների հատկությունները։ Կանխատեսման ճշգրտությունը ստուգելու համար գիտնականներն օգտագործեցին տվյալների բազաների այն մոլեկուլները, որոնցով ուսուցում չէին իրականացրել։ Նրանք այդ մոլեկուլները տվեցին մոդելին՝ հրահանգելով կանխատեսել դրանց հատկությունները, ապա նրա կանխատեսումները համեմատեցին բազաներում առկա տվյալների հետ։ Արդյունքները գոհացնող էին․ BARTSmiles-ը կարողանում էր բավականին մեծ ճշտությամբ կանխատեսել մոլեկուլների այս երկու հատկությունները։
Ինչի՞ վրա էր հիմնվում մոդելը
Այն, թե ինչ է կատարվում մեքենայական ուսուցման մոդելների ներսում, և ինչի հիման վրա են մոդելները կանխատեսումներ իրականացնում, շատ հաճախ անհայտ է։ Այդ պատճառով էլ հաջորդ քայլով գիտնականները Բջջային տեխնոլոգիաների լաբորատորիայի տնօրեն Նելլի Բաբայանի ղեկավարությամբ փորձեցին հասկանալ, թե արդյո՞ք BARTSmiles-ը մոլեկուլների հենց այն հատվածների հիման վրա է կանխատեսումներ իրականացնում, որոնք պատասխանատու են դրանց այս կամ այն հատկության համար։
Քիմիկոսներին ու կենսաբաններին արդեն հայտնի են, թե որևէ մոլեկուլի կոնկրետ որ հատվածն է պատասխանատու նրա այս կամ այն հատկության համար, և գոյություն ունի այդ ամբողջ ինֆորացիան պարունակող տվյալների բազա։
Հատուկ ծրագրի միջոցով գիտնականները BARTSmiles-ին հրահանգեցին կարմիրով ընդգծել մոլեկուլների այն հատվածները, որոնց վրա հիմնվելով՝ մոդելը կանխատեսել էր մոլեկուլների լուծելիությունը կամ մուտագենությունը։ Երբ BARTSmiles-ի ընդգծած կարմիր հատվածները համեմատեցին տվյալների բազայի հետ, տեսան, որ, իրոք, մոդելը մեծամասամբ կանխատեսումներ է իրականացրել հենց այդ հատկությունները պայմանավորող հատվածների հիման վրա։ Փաստորեն, BARTSmiles-ին հաջողվել էր բավականին լավ հասկանալ քիմիայի օրինաչափությունները։
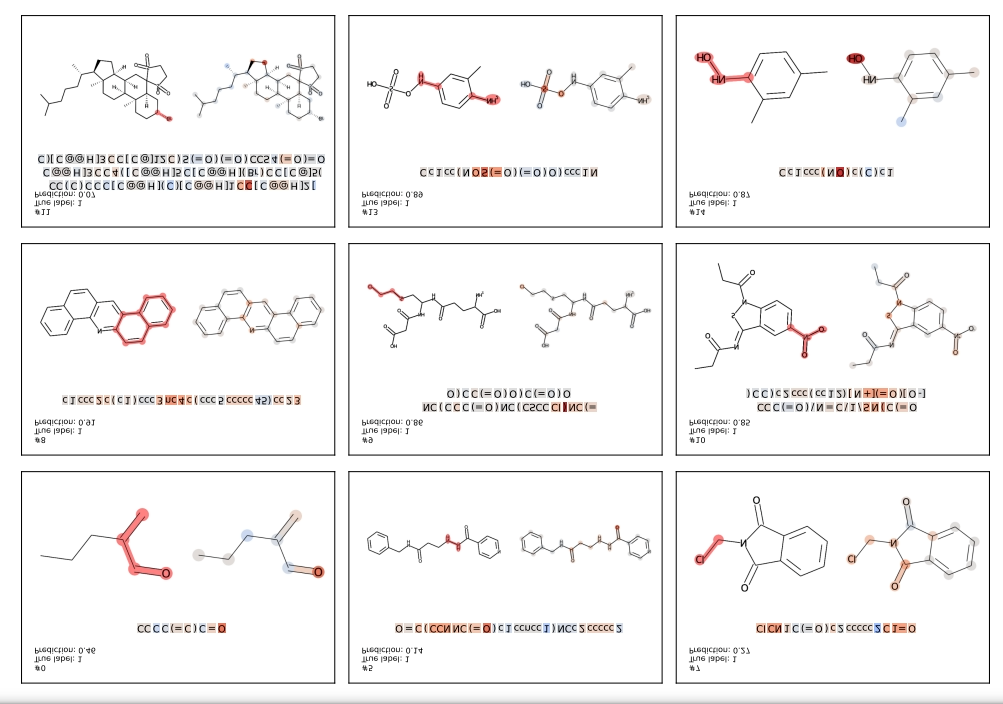
Լուսանկարում երևում են BARTSmiles-ի ընդգծած կարմիր հատվածները (աղբյուրը՝ Journal of Chemical Information and Modeling)
BARTSmiles-ը՝ մասնագիտացած
Հաջորդիվ գիտնականները տվյալների տարբեր բազաների հիման վրա BARTSmiles-ը զարգացրին ևս մի քանի ուղղություններով։ Այդ ուղղություններց մեկն, օրինակ, քիմիական ռեակցիաների կանխատեսումն էր։ Այս արդյունքը ստանալու համար գիտնականներն օգտագործեցին քիմիական ռեակցիաների տվյալների բազա, որտեղ ներկայացված են առանձին փոքր մոլեկուլներ և դրանց միջև ռեակցիայից առաջացացած ավելի մեծ մոլեկուլները, այսինքն` քիմիական ռեակցիայի ելքը։ Այս տվյալների հիման վրա վերաուսուցանվելով՝ BARTSmiles-ը սկսեց կանխատեսել, թե այս կամ այն մեծ մոլեկուլը ստանալու համար ինչ փոքր մոլեկուլներ պիտի միանան։
Այստեղ կարևոր է նշել, որ ամեն կոնկրետ խնդիր լուծելու համար գիտնականները BARTSmiles-ի հիման վրա ստանում էին առաձին նոր մոդել։ Նրանք ամեն անգամ վերցնում էին BARTSmiles-ը, որը, հիշեցնենք, 1,7 միլիարդ մոլեկուլների կառուցվածքներով ուսուցանվելով, սովորել էր տարրական քիմիա, և նրան որևէ բազայի տվյալներով վերաուսուցանելով՝ ստանում կոնկրետ խնդիր լուծող առանձին մոդել։
Զավեն Նավոյանն ասում է՝ սա նույնն է, թե մի քանի դպրոցականներ դպրոցն ավարտեն միևնույն բազային գիտելիքներով, ու նրանցից ամեն մեկը սովորի առանձին մասնագիտություն՝ դառնալով բժիշկ, իրավաբան կամ երաժիշտ։ Հենց այս ձևով էլ միևնույն հիմքի՝ տարրական քիմիա իմացող BARTSmiles-ի հիման վրա գիտնականները ստացան «մասնագիտացած» առանձին մոդելներ։
BARTSmiles-ը հատկություններ կանխատեսելիս դժվարանում էր միայն այն դեպքում, երբ հանդիպում էր յուրահատուկ մոլեկուլների։ Սովորաբար, նման կառուցվածք ունեցող մոլեկուլներն ունենում են նմանատիպ հատկություններ։ Սակայն լինում են առանձնահատուկ դեպքեր, երբ մոլեկուլում չնչին փոփոխությունը բերում է նաև հատկության էական փոփոխության, օրինակ՝ մեկ ատոմի փոփոխությամբ թունավոր նյութը դառնում է անվտանգ։ Հաշվի առնելով, որ BARTSmiles-ը կանխատեսումներ իրականացնում էր կառուցվածքների հիման վրա, մոդելը մոտ կառուցվածքներով մոլեկուլների համար կանխատեսում էր միևույն հատկությունը։ Սակայն այսպիսի առանձնահատուկ դեպքերում այն երբեմն սխալ կանխատեսումներ էր իրականացնում։
Մնացյալ դեպքերում BARTSmiles-ը լավ արդյունքներ էր ցույց տալիս․ այս մասին է փաստում այն, որ գիտնականներն իրենց մոդելի տված արդյունքները համեմատեցին մոլեկուլների տարբեր հատկութուններ կանխատեսող այլ մոդելների հետ։ Որոշ մոդելների դեպքում արդյունքը նույնական էր, ինչ-որ դեպքերում BARTSmiles-ը զիջում էր, բայց դեպքերի մեծ մասում այն ավելի լավ արդյունքներ էր ցույց տալիս, քան գոյություն ունեցող մոդելները։
BARTSmiles-ը հասանելի է համացանցում։ Մոդելի հիման վրա գիտական տարբեր թիմեր կարող են հետագա վերաուսուցմամբ նոր մոդելներ ստանալ, որոնք կոնկրետ խնդիրներ կլուծեն, օրինակ՝ նոր մոլեկուլների հատկություններ կկանխատեսեն։ Իսկ մոլեկուլների հատկությունների և քիմիական ռեակցիաների կանխատեսումը կարևոր է նյութագիտության, դեղագործության մեջ և այլ ոլորտներում, քանի որ այս կամ այն նպատակով որևէ մոլեկուլ կիրառելու համար կարևոր է, որ այն, առաջին հերթին, թունավոր չլինի մարդկանց համար, ինչպես նաև ունենա անհրաժեշտ հատկությունները։
Այսպիսով, այս հետազոտությամբ գիտնականները ստացան իրենց հարցի պատասխանը․ լեզվական մոդելը, կարդալով տեքստի վերածված մոլեկուլները, կարող է քիմիա սովորել և մոլեկուլների հատկություններ կանխատեսել։
Գիտական հոդվածն ամբողջությամբ հասանելի է այստեղ
Գլխավոր լուսանկարը գեներացված է արհեստական բանականությամբ
Հեղինակ՝ Աննա Սահակյան
Տեքստի պատրաստմանն աջակցել են Բջջային տեխնոլոգիաների լաբորատորիայի գիտնականները


